Model customization introduces new concepts to existing text-to-image models, enabling generation of the new concept in novel contexts. However, such methods lack accurate camera view control w.r.t the object, and users must resort to prompt engineering (e.g., adding ``top-view'') to achieve coarse view control. In this work, we introduce a new task -- enabling explicit control of object viewpoint for model customization. This allows us to modify object properties amongst various background scenes via text prompts, all while incorporating the target camera pose as additional control. This new task presents significant challenges in merging a 3D representation from the multi-view images of the new concept with a general, 2D text-to-image model. To bridge this gap, we propose to condition the 2D diffusion process on rendered, view-dependent features of the new object. During training, we jointly adapt the 2D diffusion modules and 3D feature predictions to reconstruct the object's appearance and geometry while reducing overfitting to the input multi-view images. Our method performs on par or better than existing image editing and model personalization baselines in preserving the custom object's identity while following the input text prompt and camera pose for the object.
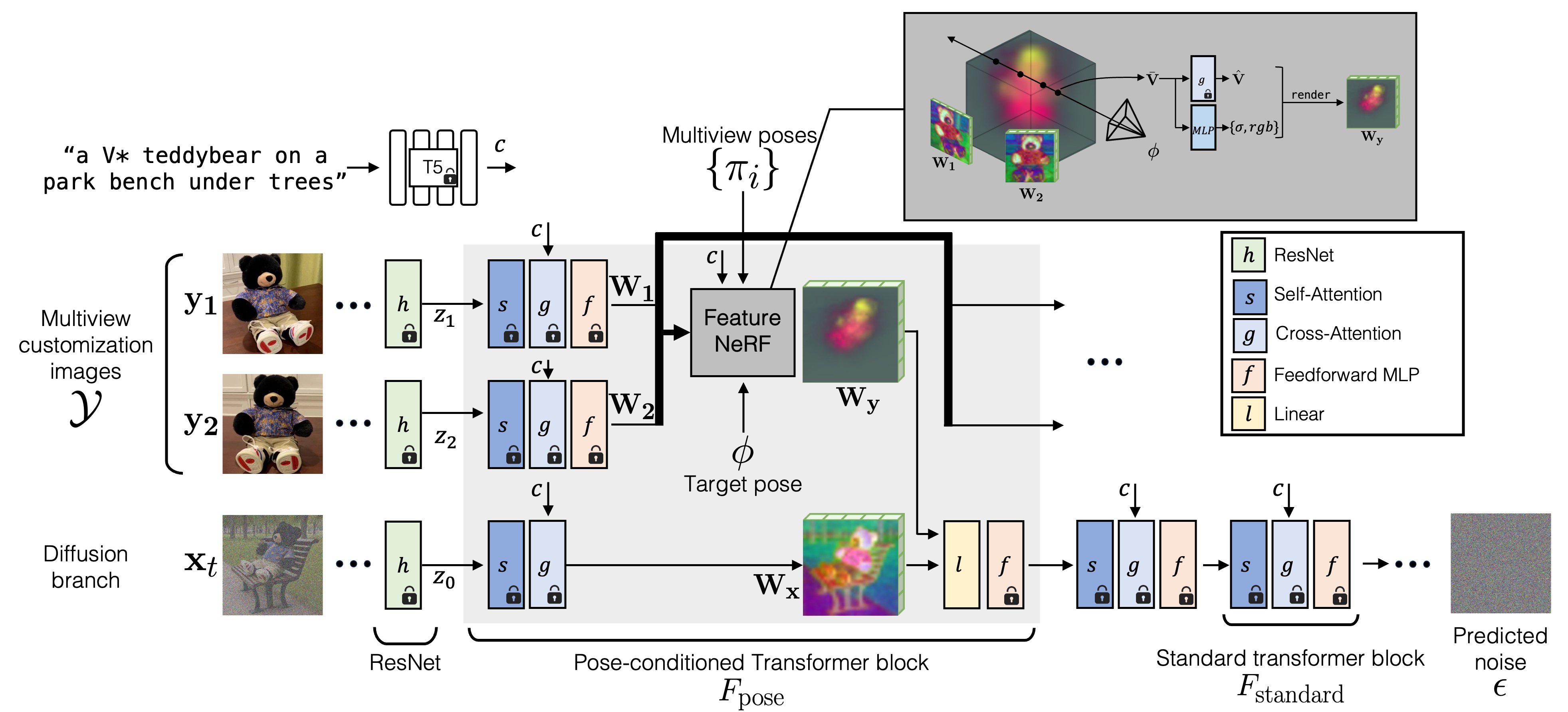
Given multi-view images of a target concept Teddy bear our method customizes a text-to-image diffusion model with that concept with an additional condition of target camera pose. We modify a subset of transformer layers to be pose-conditioned. This is done by adding a new FeatureNeRF block in intermediate feature space of the transformer layer. We finetune the new weights with the multiview dataset while keeping pre-trained model weights frozen.


We show that our method can be used in various applications like generating the object in varying pose while keeping the same background using SDEdit or generating nice panorama scenes. We can also compose multiple instances of the object in FeatureNeRF space to generate scenes with desired relative camera pose between the two.

Our method has still various limitations. It fails when we extrapolate the target camera pose far from the seen training views. The SDXL model has a bias to generate front facing object in such scenarios. It also sometimes fails to incoroporate the text prompt, especially when composing with another object.

@inproceedings{kumari2024customdiffusion360,
author = {Kumari, Nupur and Su, Grace and Zhang, Richard and Park, Taesung and Shechtman, Eli and Zhu, Jun-Yan},
title = {Customizing Text-to-Image Diffusion with Object Viewpoint Control},
booktitle = {SIGGRAPH Asia},
year = {2024},
}
We are thankful to Kangle Deng, Sheng-Yu Wang, and Gaurav Parmar for their helpful comments and discussion and to Sean Liu, Ruihan Gao, Yufei Ye, and Bharath Raj for proofreading the draft. This work was partly done by Nupur Kumari during the Adobe internship. The work is partly supported by Adobe Research, the Packard Fellowship, the Amazon Faculty Research Award, and NSF IIS-2239076. Grace Su is supported by the NSF Graduate Research Fellowship (Grant No. DGE2140739).
